条件对比使用指引
为了进一步提升指标变化的归因分析效率,Bugly专业版推出了条件对比功能,帮助大家快速定位新增问题以及劣化问题。本文通过功能简介及案例分享,指导大家如何利用条件对比功能来快速归因。
功能简介
条件对比,支持用户编辑A,B两组条件,对比这两组条件下的Issue变化。
功能入口
在问题列表中,通过 条件对比 入口进入条件对比状态。如果想退出条件对比,点击 退出对比 按钮。
跟问题列表的体验一致,用户可以通过【添加字段】入口,选择期望的搜索项,以丰富搜索条件。
对比模式
当前支持 全量数据 和 Top数据 两种模式。
全量数据,分别取满足A,B两组条件的所有Issue,对比这些Issue分别在两组条件下的上报情况。
Top数据,当数据量比较大时,对比全量数据的意义不大,而且分析速度也比较慢,可以考虑使用Top数据。分别取满足A,B两组条件的 Top 10000 Issue得到两个 Top 子集,对比这两个 Top 子集下的Issue,分别在两组条件下的上报情况。
示例:A条件下包含11000个问题,标为 [x1, x2, x3,..., x11000],B条件下包含12000个问题,[y1, y2,..., y2000, x1, x2, ... ,x10000] 。
全量数据模式,则得到的对比结果列表为 [x1, x2, x2, ..., x11000, y1, y2, ..., y2000],共13000个问题。
Top数据模式,A的Top 10000问题为 [x1, x2, ..., x10000], B的Top 10000问题为 [y1, y2, ..., y2000, x1, ..., x8000] ,最后得到的对比结果列表为, [y1, y2, ..., y2000, x1, x2, ..., x10000],共12000个问题。
对比状态
对比状态是基于A,B两组条件而言。
全量数据对比模式中,A独有的问题,标为新增问题。B独有的问题,标为已解决问题。A和B同时包含的问题,标为遗留问题。
Top 数据对比模式中,参与对比的不是全量数据,而是Top子集。A Top子集独有的问题,标为新增问题。B Top 子集的独有问题,标为已解决问题。A和B的Top子集同时包含的问题,标为遗留问题。
示例:为了简化,我们假定A条件下有[x1, x2, x3, x4, x5] 这5个问题,而B条件下有[y1, x1, x2, x3, y2, y3] 这6个问题。其中Top模式,只对比Top 3的问题。
A的Top3问题为[x1, x2, x3], B的Top3问题为[y1, x1, x2], 分别在两种对比模式下,各类问题数据如下:
| 对比状态 | 全量数据 | Top数据 |
|---|---|---|
| 新增问题 | x4, x5 | x3 |
| 已解决问题 | y1, y2, y3 | y1 |
| 遗留问题 | x1, x2, x3 | x1, x2 |
对比结果
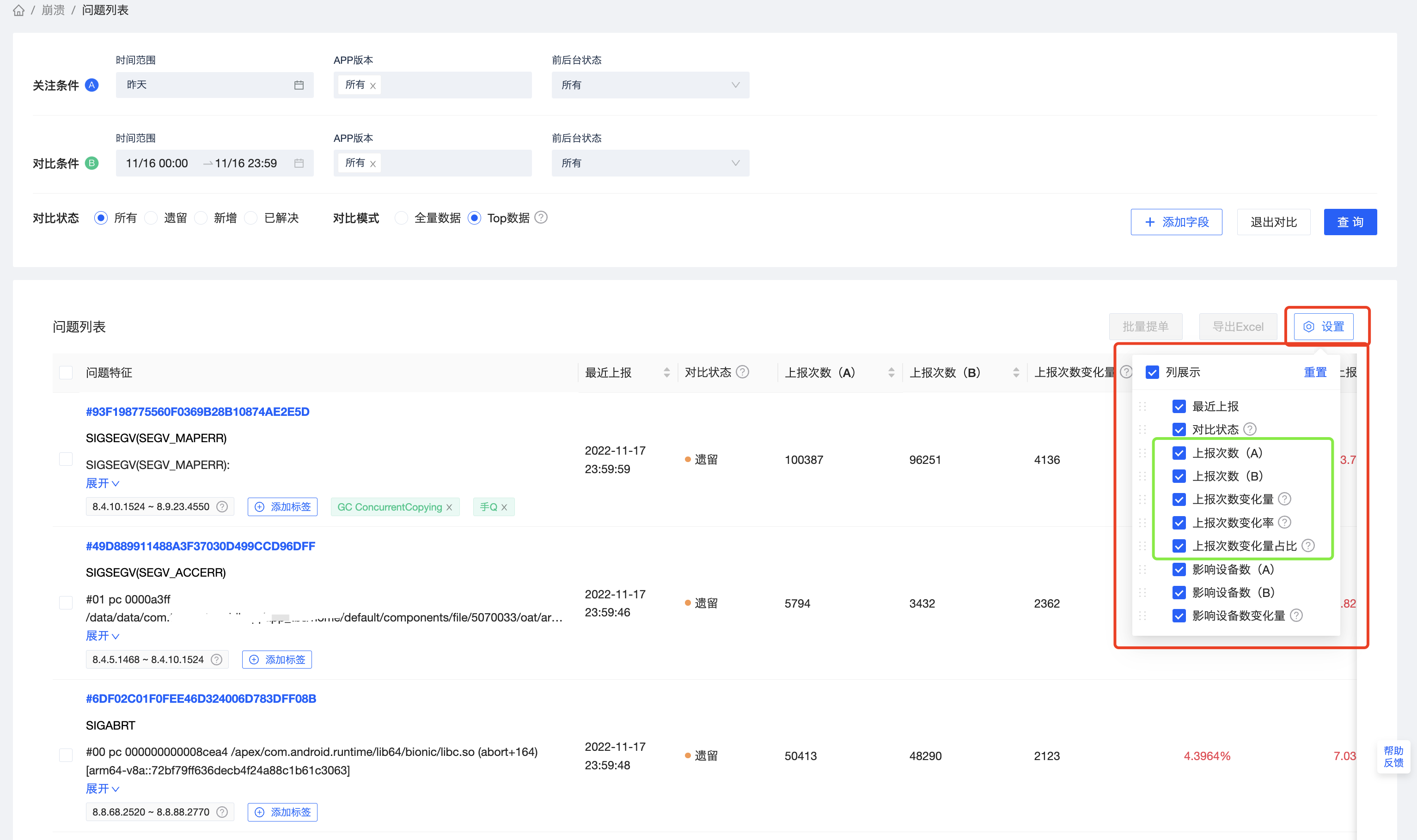
问题列表中的发生次数,影响设备数等统计字段都可参与对比。对比结果包含,每一个对比字段在条件A下的结果和条件B下的结果,以及这个对比字段在两组条件下的变化量。有些对比字段(发生次数,影响设备数)还包含变化量占比。用户可以通过表头右上角的 设置 来选择显示自己关注的字段,以及调整字段的显示顺序。
以崩溃的发生次数为例,介绍对比结果中的字段含义:
总的变化量 = A条件下总的发生次数 - B条件下总的发生次数
发生次数(变化量)= 发生次数(A)- 发生次数(B)
发生次数(变化量占比)= 发生次数(变化量)/ 总的变化量
发生次数(变化率)= 发生次数(变化量)/ 发生次数(B)
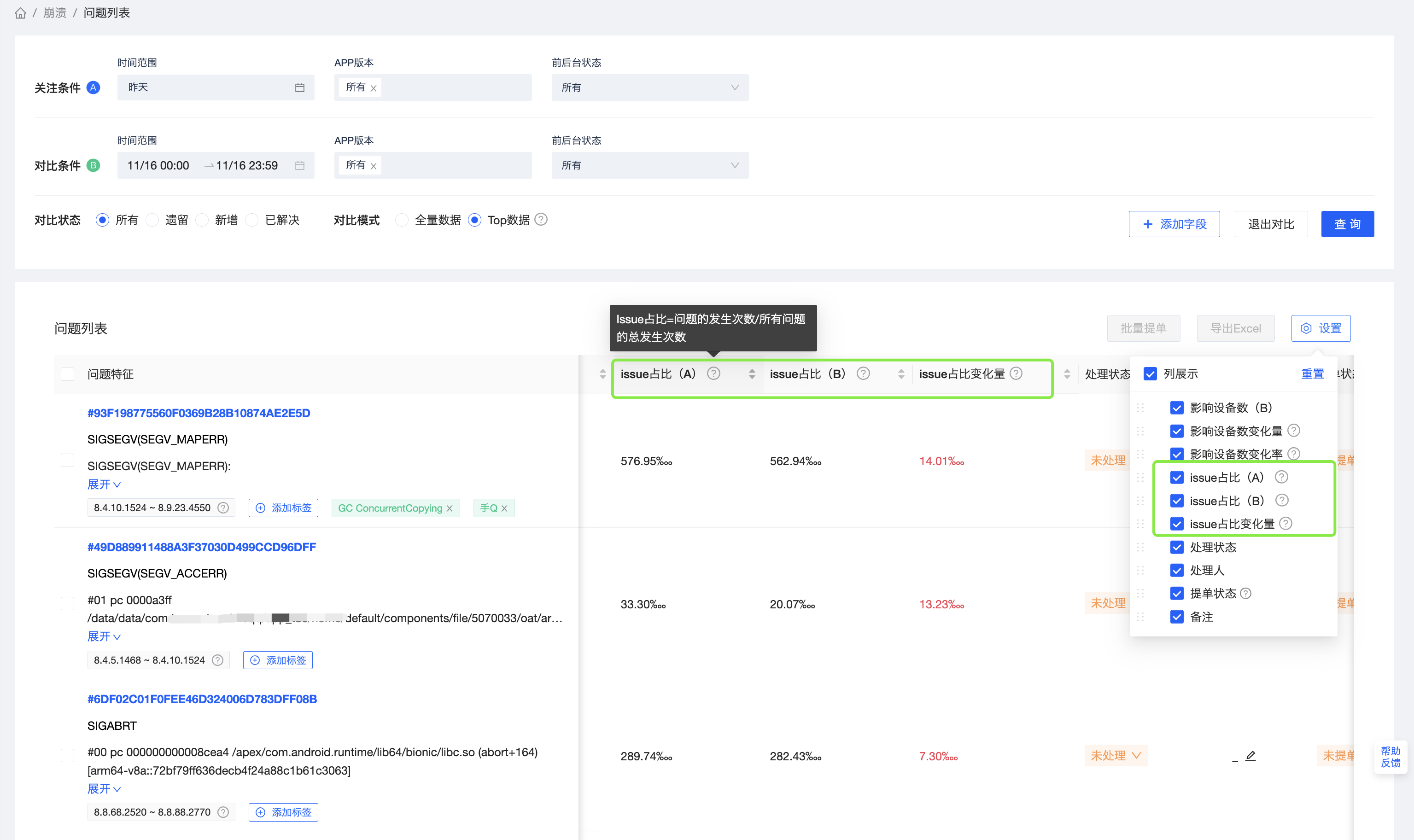
对比结果中,还增加了Issue占比的维度,通过发生次数来统计Issue在各条件下的占比。
Issue占比(A)= Issue在条件A下的发生次数 / 条件A下所有问题的发生次数
案例分享
下面通过几个具体的案例来演示一下条件对比功能的使用。
案例一:分析崩溃率爆增原因
甲业务,某天突然收到大量崩溃的告警以及反馈,如果想快速定位问题的原因,可以使用条件对比功能。
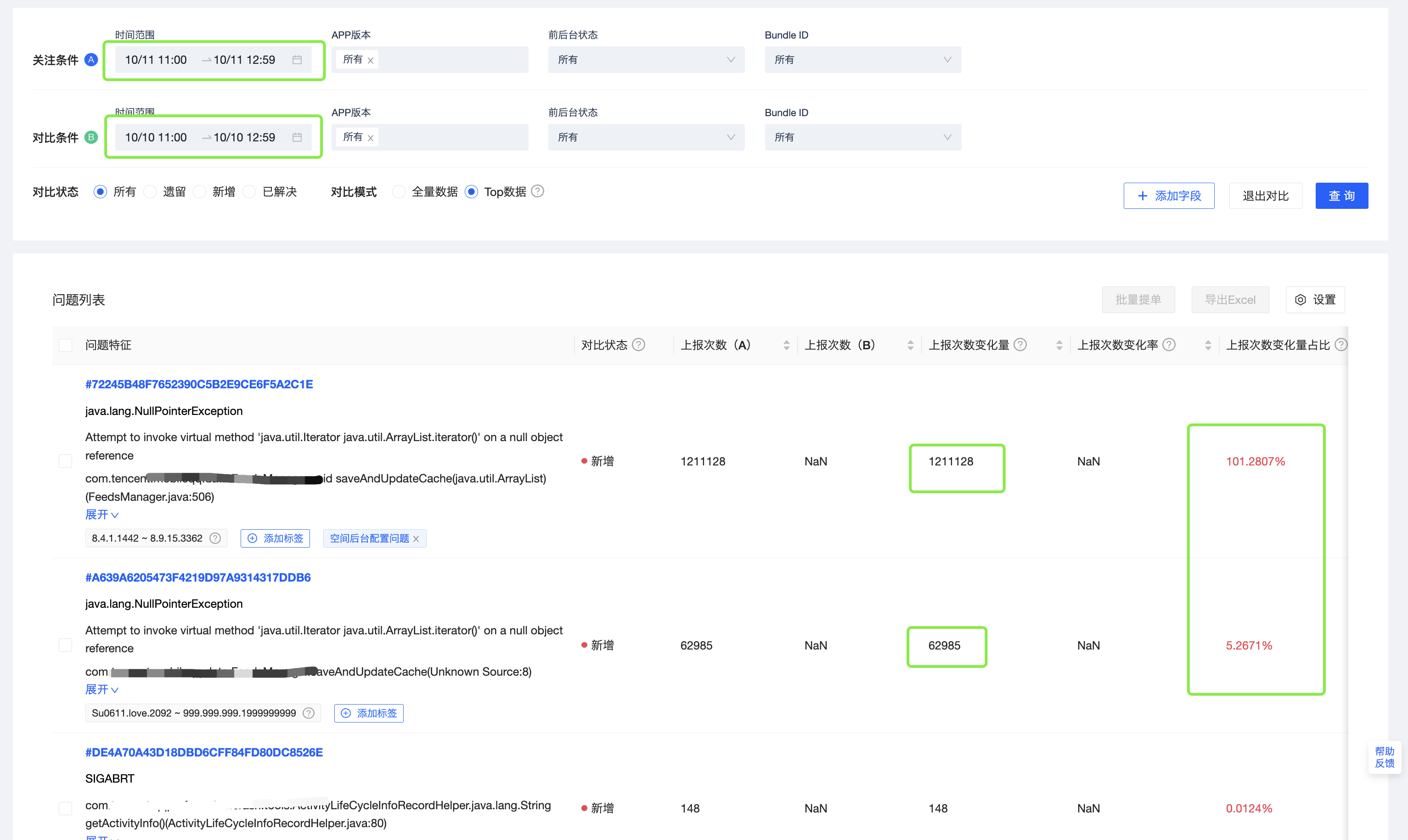
如下图所示,大量告警发生在12:00左右,崩溃率也持续在爆涨。这种情况下,可以选择两组对比条件,用10月11日从11点到12点的数据,对比前一天11点到12点的数据,分析导致崩溃率爆涨的原因。
结果看到,有三个新增问题,其中前两个问题占比非常高。看上报次数变化量以及变化量的占比可以看到,Top2的问题都属于新增问题,而且上报次数变化量占比106.54%,可以推断这两个新增问题为本次崩溃率爆涨的主要原因。
这里上报次数变化量占比会超过100%的原因是,上报次数变化量占比 = (上报次数(A)- 上报次数(B))/(条件A总的上报次数 - 条件B总的上报次数)。也就是说,如果一个Issue其上报交数变化量,比条件A和条件B总的上报次数变化量还大,就超过100%了。因为,虽然整体上条件A的崩溃率爆涨了,但是对于个别问题,条件A下,还是有可能比条件B下,上报更少的。
案例二:分析开发版本的新增卡顿问题
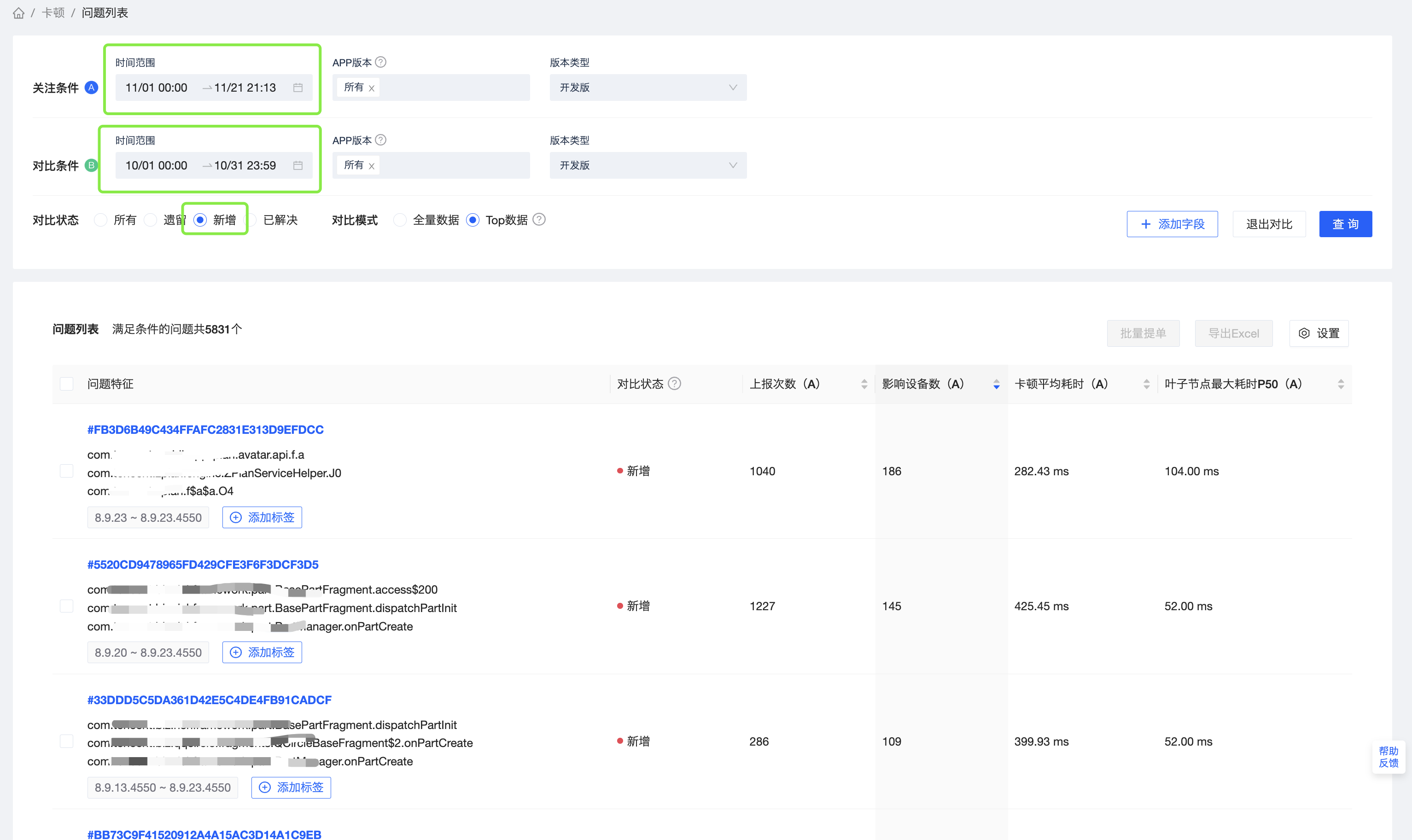
乙业务,计划发版本了,在测试周想确认一下开发期间有没有引入新的问题。这种情况下,对比条件可以指定,查看开发版的数据,分别对比上个版本的开发周期,跟这个版本开发周期内,有哪些新增问题。根据发生次数,影响设备数,以及卡顿平均耗时,叶子结点最大耗时P50,可以快速发现开发期间引入的新增问题。
案例三:分析两个线上版本的Issue差异
丙业务,发布新版后,发现新版的崩溃率翻了1倍。业务想分析,最近7天,最新版本跟次新版本之间,是哪些问题变化导致了崩溃率劣化严重。
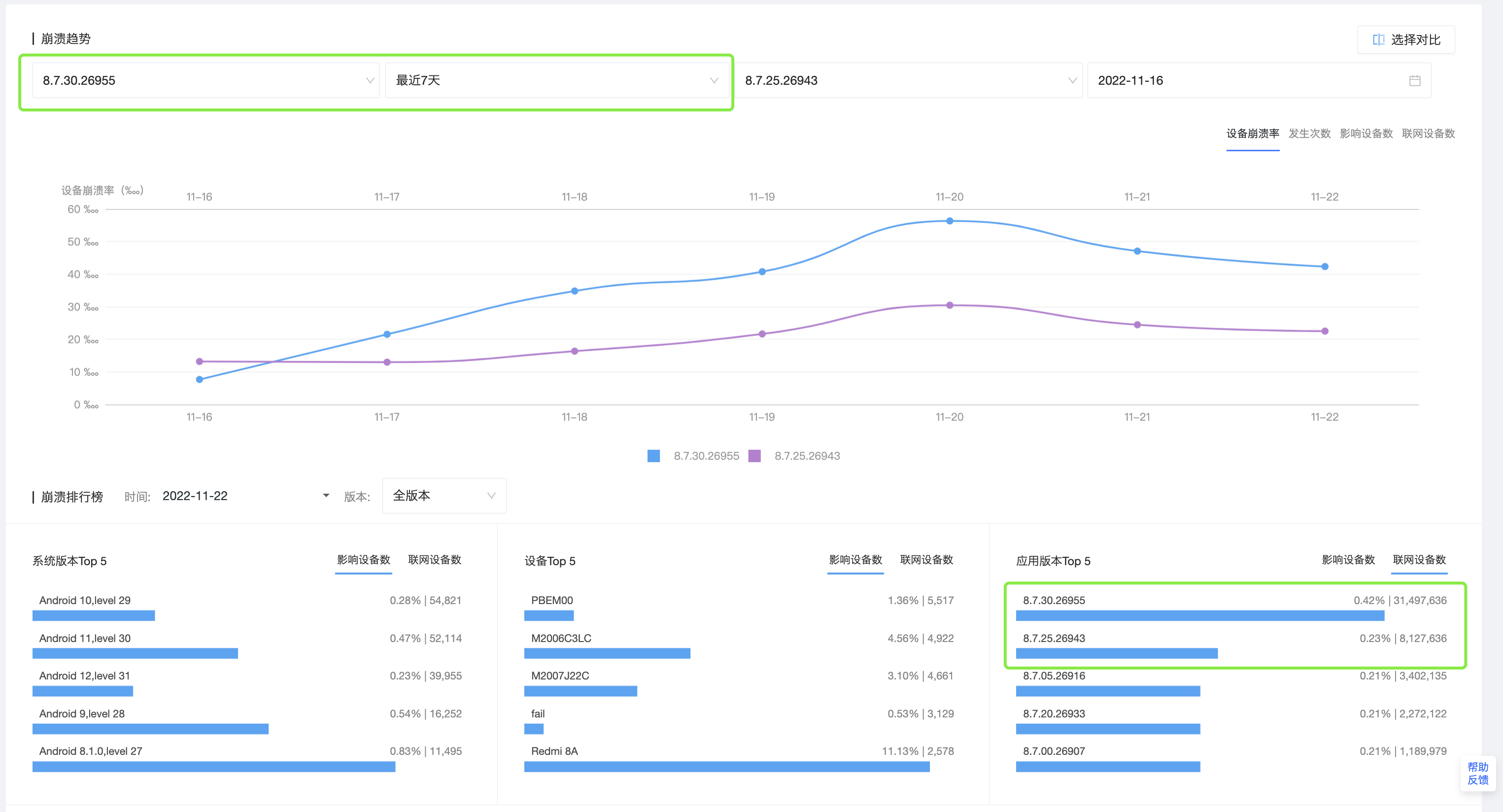
最近7天,分别选择两个版本对比。这里,为了准确识别新增问题,对比模式选择了全量数据。分析对比结果看到,导致崩溃率劣化的原因比较复杂,既有历史问题的恶化,也包含新增问题。另外问题也相对比较分散,并不是集中在几个问题。上报次数变化量Top40的问题,占了整体变化量的74%左右,剩下的都是长尾数据。
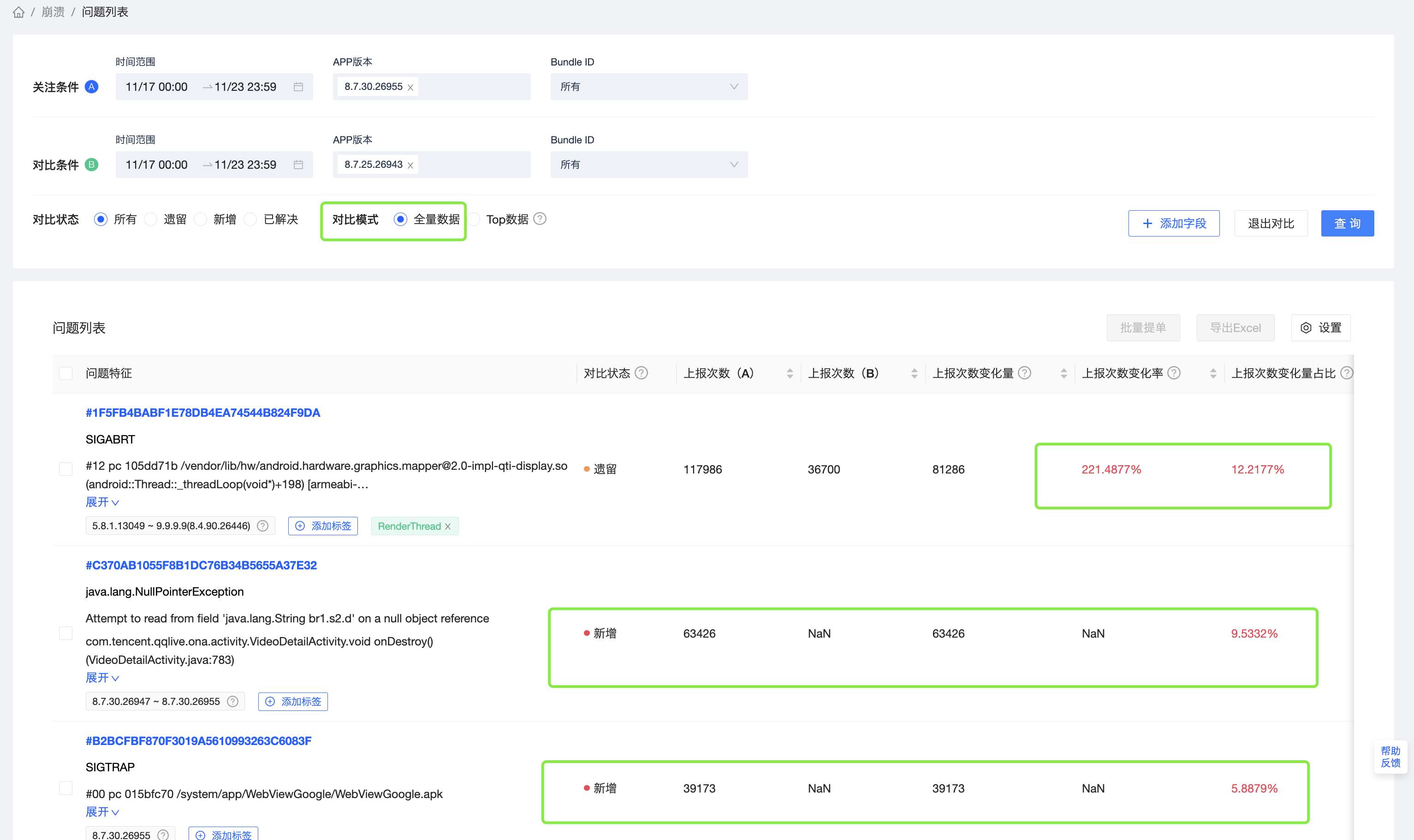
案例四:分析两个不同机型的Issue差异
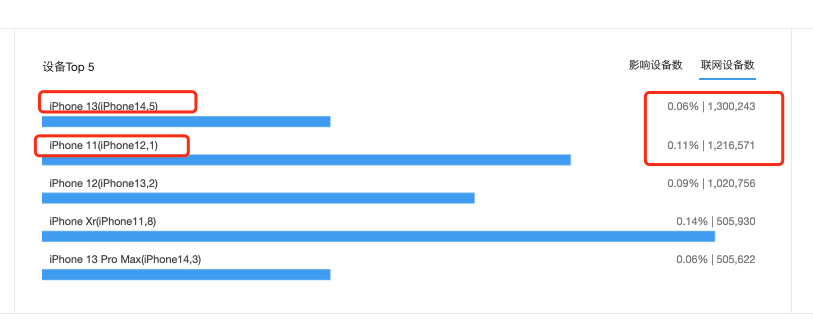
丁业务,分析11月28日的数据发现,iPhone 13 和 iPhone 11 虽然联网设备数差不多,但是机型的设备崩溃率和影响设备数,相差近1倍。
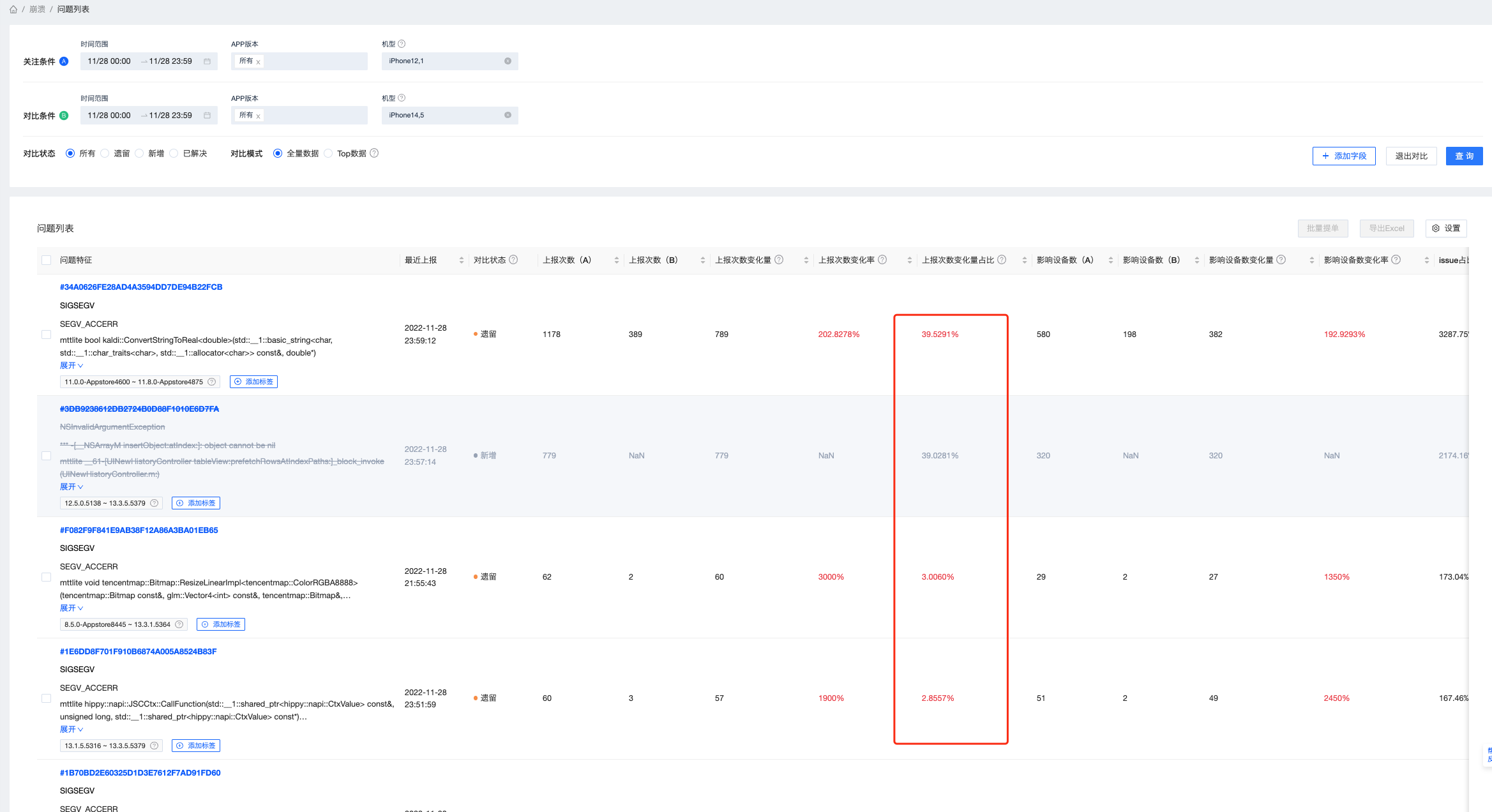
为了找到两个不同设备的Issue差异,对比分析同一天,不同机型的数据,如下图所示,3个遗留问题和一个新增问题是主要原因。
FAQ
问题1:全量数据和Top数据有什么差异?
全量数据是指,分别取满足A,B两组条件的所有Issue参与对比。而Top数据是指,分别取满足A,B两组条件下的Top Issue参与对比。也就是说,对比的Issue范围是不同的。
例如,Issue X 标识为新增问题,如果在全量数据的对比模式下,则说明Issue X 在条件B中没有上例上报。但是,如果在Top 数据模式中,只能说明Issue X 不属于条件B的Top 10000问题,并不表示在条件B下没有上报。也就是说有可能有上报,也有可能没有问题。具体要看条件B的Issue情况。
问题2:新增问题的判定规则?
对比状态的选取是基于两组对比数据而言的,有两个数据集,同时出现在两个数据集中的,标为遗留问题。如果只出现在条件A提取的数据集中,则标识为新增问题。如果只出现在条件B提取的数据集中,则标为已解决问题。
由于两组条件A,B提取结果集的方式有两种,全量数据模式,和Top数据模式,因此对于新增问题和已解决问题,有可能在不同的对比模式下,状态会变化。遗留问题则无论是哪种模式,都是一样,表示同时出现在两组条件提取的结果集中。
问题3:已解决的问题的判定规则?
对比状态的选取是基于两组对比数据而言的,有两个数据集,同时出现在两个数据集中的,标为遗留问题。如果只出现在条件A提取的数据集中,则标识为新增问题。如果只出现在条件B提取的数据集中,则标为已解决问题。
由于两组条件A,B提取结果集的方式有两种,全量数据模式,和Top数据模式,因此对于新增问题和已解决问题,有可能在不同的对比模式下,状态会变化。遗留问题则无论是哪种模式,都是一样,表示同时出现在两组条件提取的结果集中。
所以,这里的已解决跟问题是否真正已经解决是没有必然关系的。
问题4:为什么结果中有NaN?
在两个结果集进行对比时,有可能存在某个Issue X 只出现在一个结果集中,另一个结果集中没有,即新增问题,或者已解决问题。这种情况下,对于没有结果的那一组数据,就默认用NaN来标识。
例如,新增问题,没有出现在条件B的结果集中,条件B的统计数据都标为NaN。而已解决问题,则没有出现在条件A的结果集中,条件A的统计结果标为NaN。
问题5:为什么XX的变化量占比会超过100% ?甚至有负数?
以发生次数为例来解释一下,假定条件A,B的结果集包含三个Issue X,Y, Z。
| Issue | 条件A下的发生次数 | 条件B下的发生次数 |
|---|---|---|
| X | 200 | 100 |
| Y | 10 | 20 |
| Z | 20 | 30 |
发生次数总的变化量 = (200 + 10 + 20) - (100 + 20 + 30) = 80
Issue X 的发生次数变化量 = 200 - 100 = 100
Issue X 的发生次数变化量占比 = 100 / 80 = 125%
Issue X 的发生次数变化率 = 100 / 100 = 100%
因为Issue Y 和 Issue Z 在条件A下的发生次数小于其在条件B下的发生次数,因此这两个Issue对于总的变化量是负贡献,得到的变化量占比也是负数。
Issue Y 的发生次数变化量占比 = (10 - 20)/ 80 = -12.5%
Issue Z 的发生次数变化量占比 = (30 - 20) / 80 = -12.5%
因此,如果变化量占比 > 0 ,说明当前Issue的变化量,对于整体变化量是正向贡献。如果变化量占比 < 0 , 说明当前Issue的变化量,对于整体变量量是负贡献。
问题6:变化量占比和变化率的区别?
变化量占比 = 变化量 / 总的变化量,而 变化率 = 变化量 / 字段在条件B下的统计值。变化率用来分析,这个统计字段,在两组条件的变化情况。变化量虽然可以反应变化情况,为什么还需要引入变化率呢?因为不同的Issue,历史的上报量本身就有所不同。
| Issue | 条件A下的发生次数 | 条件B下的发生次数 |
|---|---|---|
| X | 11k | 1K |
| Y | 680K | 660K |
假定在某次灰度中,发现对比上次灰度版本,Issue X , Y 的发生次数有了变化。其中X的变量化是10K,而Y的变化量是20K。如果判断X,Y这两个Issue,哪个更加严重,需要优先跟进呢?显然,虽然Y的变化量比较大,但是X的变化率更大,问题发生概率增加了10倍。说明本次灰度的变化,导致了X问题发生的概率大大增加,存在比较大的质量风险。
变化量占比往往用在指标劣化的归因分析上。两组条件下,A条件的指标比B条件明显劣化了,可以通过变化量占比,快速找到是哪些Issue的变化导致的指标劣化。