Java内存详情
一、 功能背景
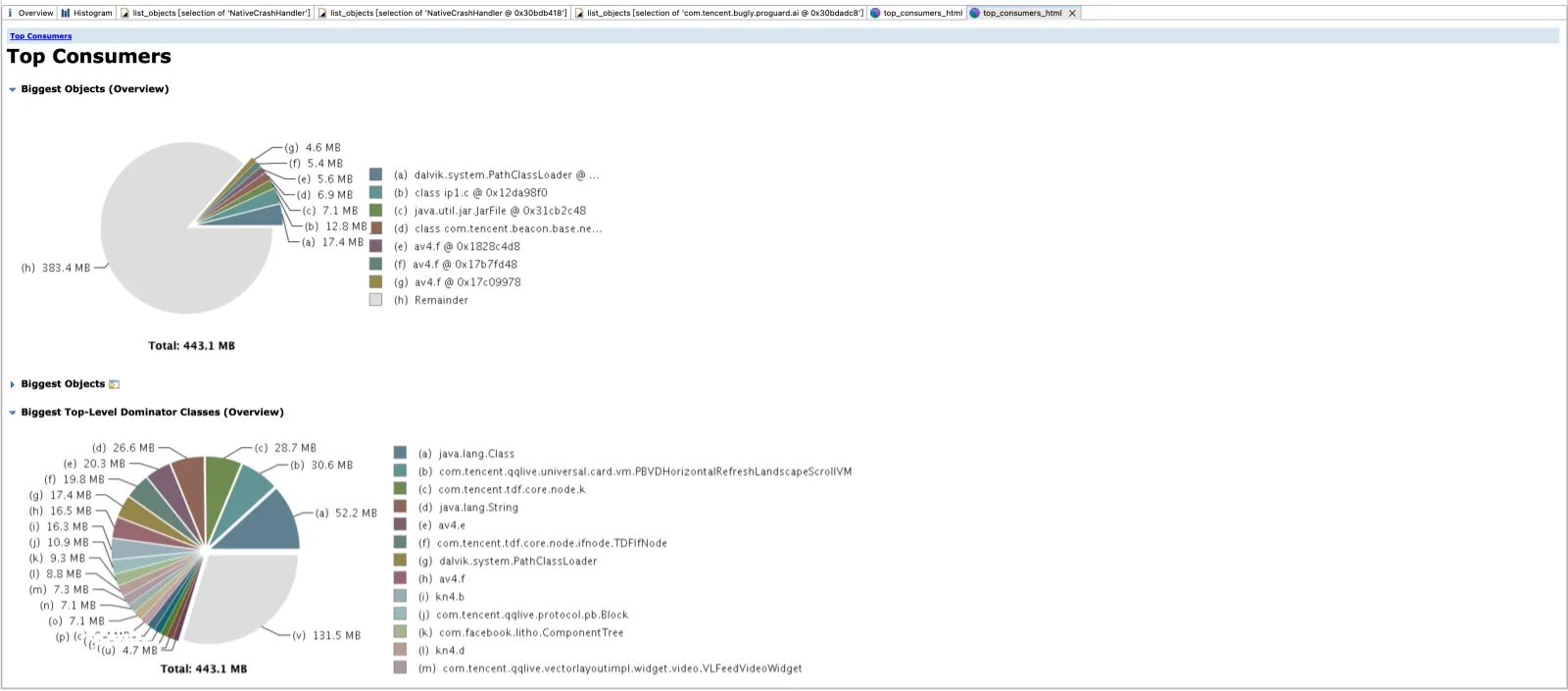
无论在Android中还是Java中,每个虚拟机实例都有一个可用堆内存的上限值,在Android中,这个值一般是256MB(如果在Manifest文件中开启large heap属性,这个值可能更高),运行过程中,虚拟机实例内存如果超过这个值,就可能触发 java.lang.OutOfMemoryError 异常,之前我们一般会通过MAT的 ”Top Consumers“ 功能来查看堆内存转储hprof文件里面哪些对象的内存占用比较大,哪类对象的数量多等等,然后再查看这些对象的GC 引用链来查找为什么这些对象没有被释放(是泄漏还是被误用)。
通过MAT的这个能力,我们一般都能比较快速的分析出问题原因,但是MAT是一个PC端的工具,针对Android这种移动端的使用场景来说会有如下一些缺点:
无法准确获取用户侧的hprof堆转储文件,没有hprof文件,根本无法使用MAT分析;
无法还原引用链里面的类名和成员变量名,分析的时候还得手动对照mapping文件来翻译,使用极其不方便;
只能针对单个用户的上报作分析,无法聚类分析大盘用户的数据,找到Top问题;
很难基于MAT做二次开发,无法实现一些定制化的功能;
二、功能简介
因为MAT工具的这些限制,它无法满足线上监控Java内存的需求,而很多业务其实都有线上监控的需求,基于此Bugly建设了Java内存详情分析功能,它是可以在线随时开启和关闭的,十分方便,相比MAT工具主要功能和优化点如下所示:
- 实现了类似”Top Consumers“的能力,可以分析出 ”泄漏对象“、”单个大对象“、”密集大对象“ 等问题; 智能分析出用户关心的Java内存问题,不需要用户每次都转换hprof文件格式,然后拖到PC端使用MAT工具分析,极大的提升了分析效率.
- 在频繁GC或者连续多次达到Java堆内存最大值的某个阈值的时候,在移动端通过子进程自动dump Java堆内存转储文件; 在后台dump堆内存转储文件,对用户体验影响很小,解决了在合适的时机获取堆内存转储文件的问题.
- 可以在线使用,同时利用Bugly已有的翻译能力,翻译类名和成员变量名之后,再智能提取聚类关键特征,将相似的问题聚类到一起; 自动翻译和聚类,让用户可以轻松聚焦Top问题,同时也解决了手动翻译的繁琐操作问题.
关于泄漏对象、单个大对象、密集大对象的定义说明如下:
泄漏对象:目前支持检测泄漏的Activity对象;
单个大对象:与MAT对应的是 ”Biggest Objects“ 功能,即其Retained Size大于某一个阈值的单个Java对象或者类,该阈值目前由Bugly后台指定;
密集大对象:与MAT对应的是 ”Biggest Top-Level Dominator Classes“ 功能,即某一Java类,虽然其单个对象小,但是其所有的Java对象实例的总Retained Size和超过某一个阈值,该阈值目前由Bugly后台指定;
三、客户端使用指南
3.1、开启方式
需要升级到 Bugly 4.4.2.2 之后的版本才支持Java内存详情监控功能,客户端可以通过如下方式开启,同时配合后台新建采样配置项来开启。
- 客户端
public static void initBugly(Context context) {
// 1. 初始化参数预构建,必需设置初始化参数
String appID = "xxxxxxx"; // 【必需设置】在Bugly 专业版 注册产品的appID
String appKey = "xxxxxxxxxxx"; // 【必需设置】在Bugly 专业版 注册产品的appKey
BuglyBuilder builder = new BuglyBuilder(appID, appKey);
......
// 2. 开启Java内存详情
build.addMonitor(BuglyMonitorName.MEMORY_JAVA_CEILING);
// 3. 初始化,必需调用
Bugly.init(context, builder);
}
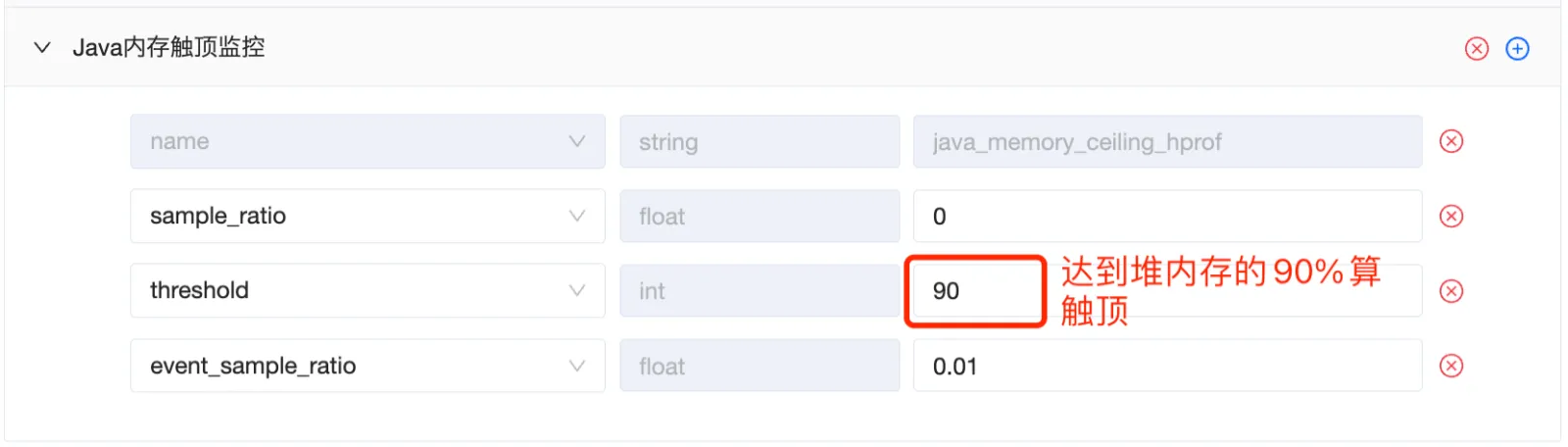
- 配置项 sample_ratio: 控制用户采样率,即多少设备会开启这个功能; event_sample_ratio: 控制事件采样率,即发生内存触顶之后,是否需要上报; threshold:设置堆转储文件的dump时机,90 代表的是在达到最大值的90%的时候开始dump,堆内存最大值对应 Runtime.getRuntime().maxMemory();
3.2、相关日志
1、功能开启成功的日志:
07-04 10:xx:xx.xxx 14546 1819 D RMonitor_MemoryCeiling: Start MemoryCeilingMonitor
07-04 10:xx:xx.xxx 14546 1819 D RMonitor_MemoryCeiling: start detect memory ceiling
2、检测到Java内存触顶,开始dump日志文件:
07-04 10:xx:xx.xxx 3713 3713 I .example.sdkapp: hprof: heap dump "/storage/emulated/0/Android/data/com.example.sdkapp/files/Tencent/RMonitor/main/Log/dump_LowMemory_24-07-04_10.20.41.hprof" starting...
3、上报日志文件到Bugly后台的日志(WiFi网络下实时上报,其他网络重启后上报):
07-04 10:xx:xx.xxx 14546 1918 I RMonitor_report_File: url: https://xxx.qq.com/v1/xxxx/upload-file?timestamp=1720059647340&nonce=7153357010e6227230d5deb79ce73ed7, sub_type: java_memory_ceiling_hprof
四、 Web页面使用指南
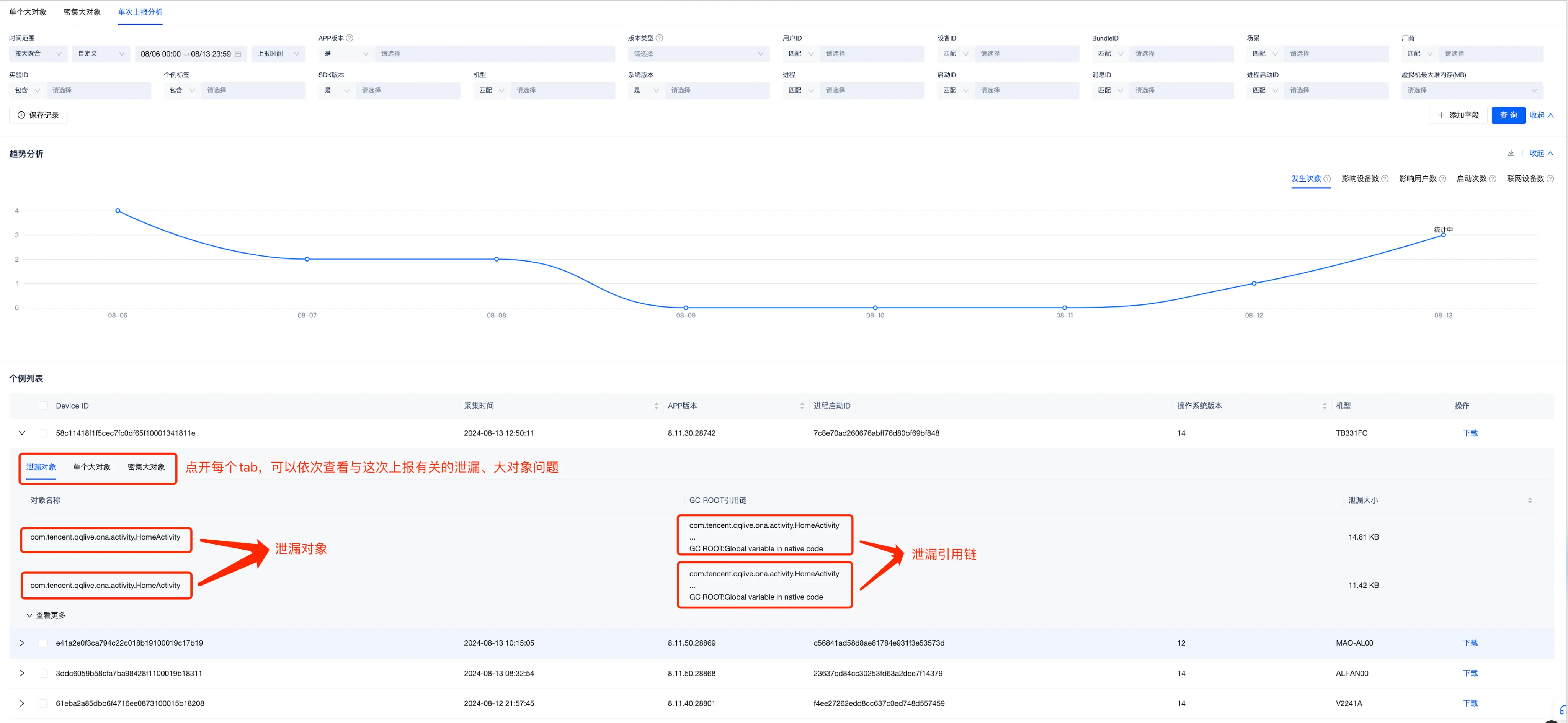
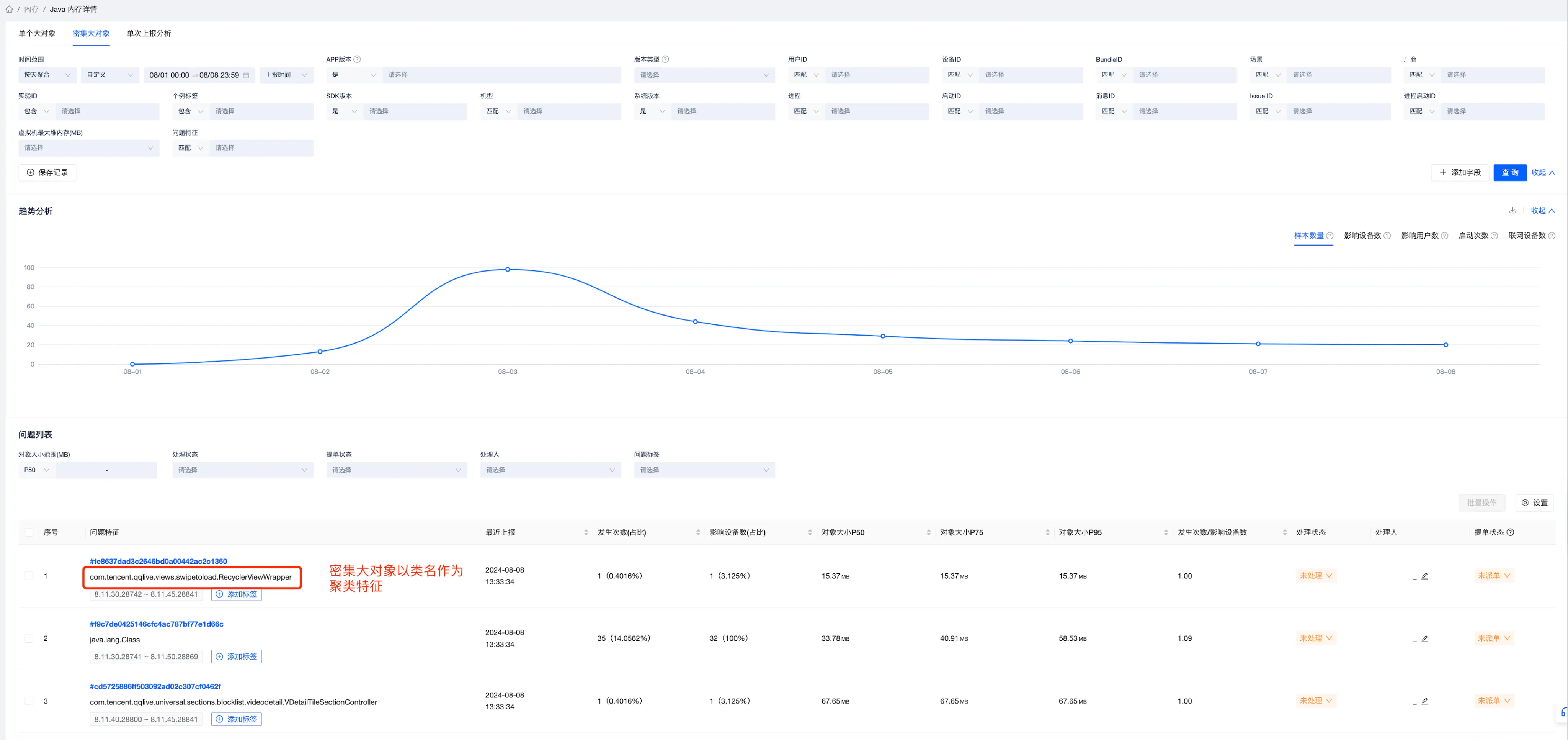
点开Java内存详情页面后,会展示单个大对象、密集大对象、单次上报分析的问题列表页面,其中单个大对象和密集大对象的问题列表会根据分析出来的问题,提取关键特征然后聚类, 以便分析Top类问题, 单次上报分析的列表是没有聚类的,但是它可以很方便的看到某次触顶上报相关的所有问题, 两个问题列表页面可以应用在不同的使用场景,而且也可以通过“点击查找”等按钮快捷跳转另一个列表页面。
目前单个大对象和密集大对象的聚类特征分为“引用链”、“支配树”、“文本”、“类名”几种类型:
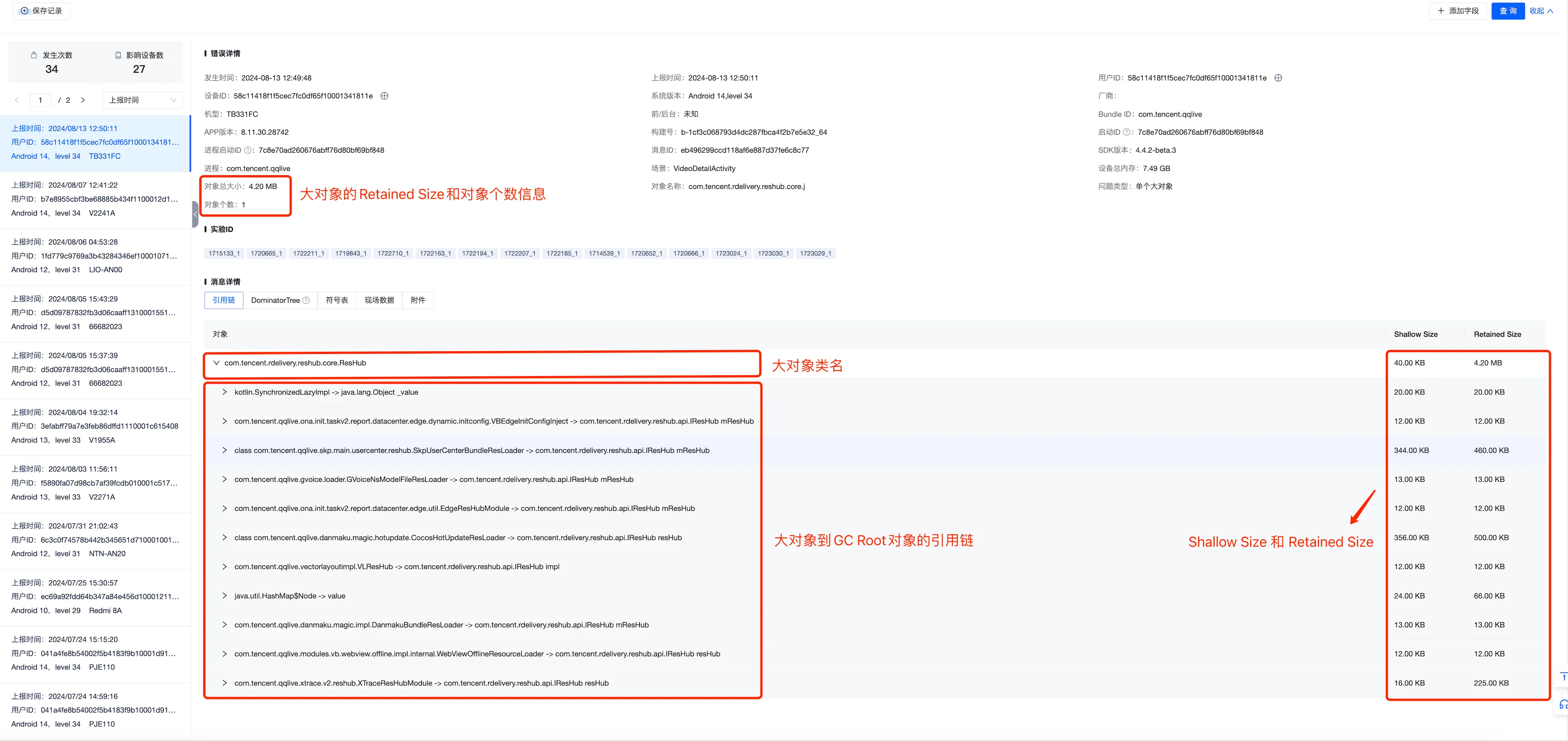
引用链也就是单个大对象到GC Root的最短引用链,比较好理解;
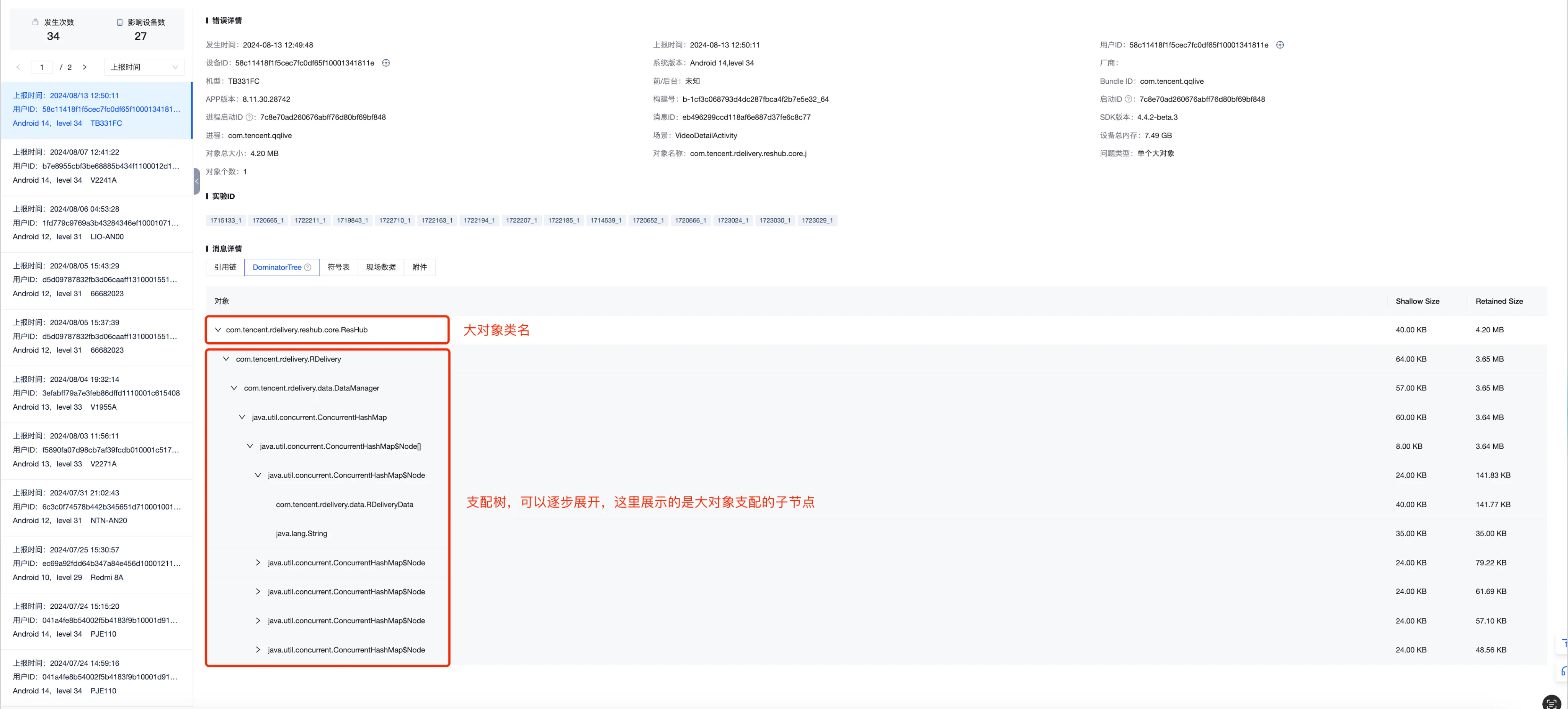
支配树 也就是DominatorTree,我们知道一个对象的Retained Size代表的是回收该对象之后,虚拟机可以回收的内存大小,该大小往往不等于Shallow Size,是因为该对象支配着其他对象,其他对象的大小也应该算到它的RetainedSize里面去,这样每一个大对象都有一棵支配树, Bugly也会把这个算作聚类特征的一种;
如果某个大对象是一个文件或者线程,可能会取它的文件路径或者线程名字来作为聚类特征;
密集大对象使用类名来作为聚类特征;
注:这里需要注意的是支配树与OutReference的区别,支配树上面存在直接父子关系的节点并不意味着存在直接的引用关系,而是可能是间接引用的对象。
4.1、问题列表页 - 单个大对象 & 密集大对象
当Bugly后台收到用户的Java内存触顶日志后,会通过自研的堆转储文件分析工具分析出“单个大对象”、“密集大对象”、“泄漏对象”等问题,每个问题都会提取其关键特征,然后根据关键特征来做聚类,所以一次上报一般会对应Bugly的多个issue,在单个大对象和密集大对象的问题列表页面主要包含“筛选项”、“上报趋势”、“问题列表”三项内容,其中:
- 筛选项 虚拟机最大堆内存(MB): 是一个下拉选择框,对应 Runtime.getRuntime().maxMemory()的值; 问题特征:可以通过“匹配”等多种方式来过滤特定特征的issue;
- 上报趋势 样本数量:对应问题列表中个例的数量;
- 问题列表
问题列表按照issue归类,每个issue有自己的关键特征,关键特征主要有三种类型 “引用链”、“支配树“、”纯文本“,引用链是大对象到GC Root的最短路径, 针对大对象是文件或者线程的,会以文件路径或者线程名字来作为聚类特征。
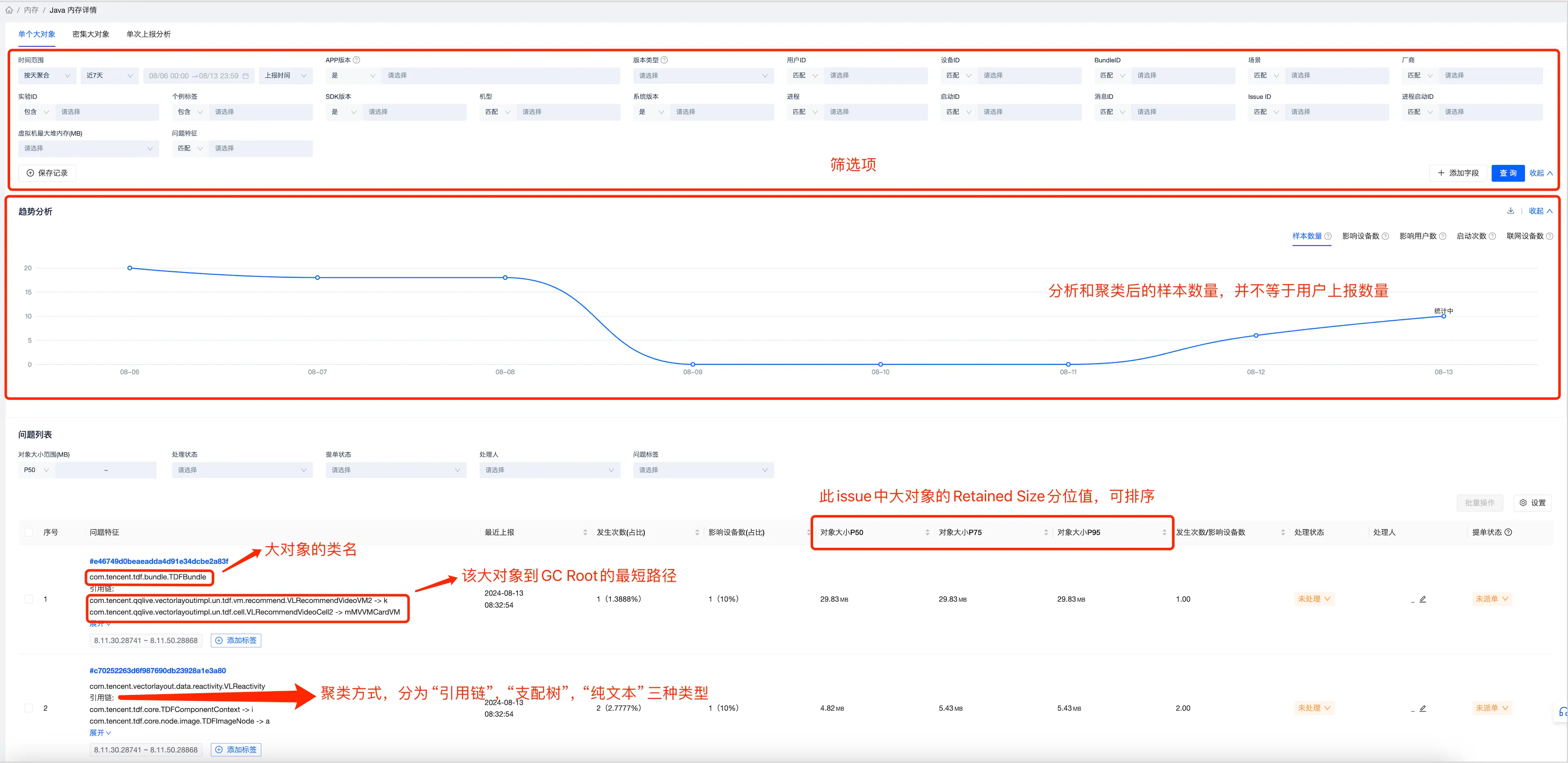
 密集大对象的聚类特征即为该大对象的类名:
密集大对象的聚类特征即为该大对象的类名:
4.2、问题详情页
单个大对象和密集大对象有对应的问题详情页,从该页面我们可以看到大对象的所有GC Root引用链和它的内存支配树,为了减少展示的层级,支配树默认只会展示大于父节点大小10%的子节点内容,如果叶子节点是数组,还会继续打印数组的元素,同时在附件tab中,可以下载原始的堆转储hprof文件,可以通过hprof-conv工具转换后,通过MAT等工具本地分析。
4.3、问题列表页 - 单次上报分析
单个大对象和密集大对象单的问题列表展示的是分析和聚类后的结果,而单次上报分析的问题列表是没有聚类的,用户的每一条上报在问题列表中会单独占一条,但是点开其中一条后,可以展示该次上报里面是否有内存泄漏问题以及所有的单个大对象和密集大对象问题,可以很方便的查看某次Java内存触顶的详细原因,同时也提供批量下载堆转储hprof文件的功能。