卡顿治理技能分享
Bugly是怎么做卡顿监控的?
萝卜兔最近开始接手一款移动端App的性能优化。由于最近反馈App卡顿的用户越来越多,因此卡顿治理成为迫在眉睫的事情。看到萝卜兔一副心事重重的样子,土豆决定推荐他使用Bugly的卡顿监控。
土豆:你可以试一下Bugly的卡顿监控,接入流程简单。
萝卜兔:Bugly是如何做卡顿监控的呢?
土豆:他们是通过监听UI线程的Handler消息的派发过程,通过派发开始和派发结束来监听消息的执行耗时。当消息耗时大于阈值时,会判定为卡顿,然后收集堆栈信息上报到后台。
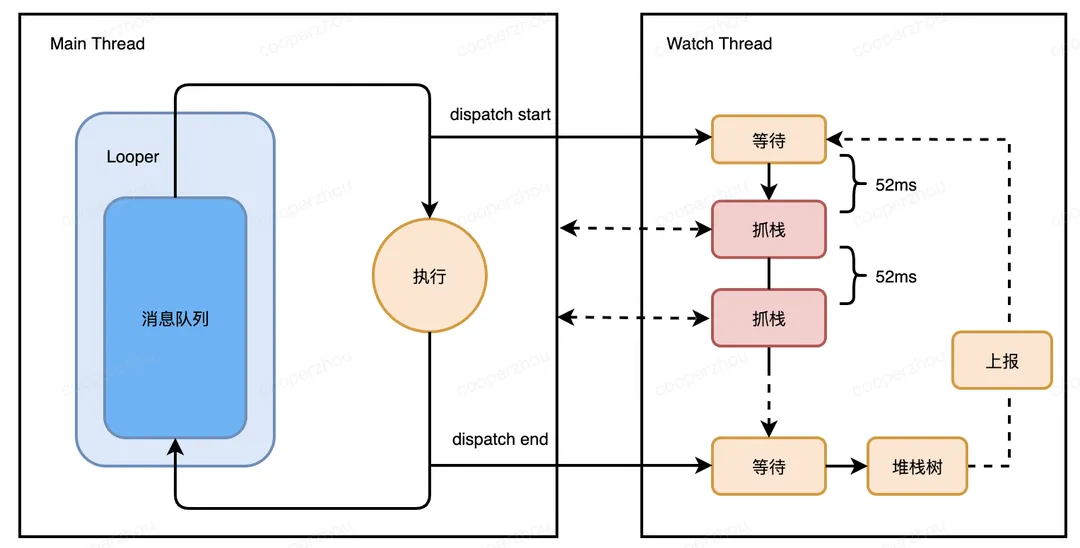

萝卜兔:监控消息执行,持续抓栈,监控过程会不会加剧卡顿呢?
土豆:可以通过配置,设置合理的事件采样,而不是直接监控每一条消息的执行。经过多个应用的实测,如何已经稳定地在多个应用的线上版本开启哦。
萝卜兔决定在接下来的灰度版本中接入试试。在官方接入文档的指导下,顺利完成接入和自测验证。
怎么进行卡顿治理?
几天后,萝卜兔一看傻眼了,Bugly平台显示,用户上报的卡顿问题有几万个。他急冲冲地跑来问土豆。
萝卜兔:土豆,Bugly平台上的问题太多了,我应该怎么办呀。
土豆:你设置的卡顿阈值是多少呢?
萝卜兔:200ms,一次消息执行耗时超过200ms,用户明显感觉到卡顿了。
土豆:在卡顿治过程中,可以分阶段来,初期阶段可以将核心放在卡顿耗时比较大的问题上。比如,你可以将卡顿阈值调整为500ms。
技能1:卡顿治过程中,分阶段调整卡顿阈值。
萝卜兔:呃,灰度已经发了,那得等下一轮灰度。现在这些数据怎么办呢?问题太多了,我不可能一个一个看。我不想加班,我不想加班,呜呜.....
土豆:别着急,你想一下,一般导致卡顿的原因有几类?
萝卜兔:UI线程读写文件,访问DB,或者跟其他的线程存在锁等待。另外,跨进程的访问也是比较耗时。还有UI过于复杂,也会导致刷新慢。之前也遇到过,高频打日志,导致卡顿明显。
土豆:对这些卡顿问题分一类,是不是可以归为三大类呢?
- 单点耗时

- 多点耗时


- 复杂或频繁执行

在治理过程中,优先解决对用户体验影响大的,影响面广的问题。对于性能治理来说,通常的治理策略是,优先防止新问题产生,逐步推动历史问题解决。
技能2:优先解决对用户体验影响大的,影响面广的问题。
技能3:优先防止新问题产生,逐步推动历史问题解决。
萝卜兔:那我应该怎样才能从这几万个问题里,找到对用户影响大,影响面广的问题呢?
土豆:一个问题上报量大,是不是表示影响面广呢?一个问题卡顿耗时特别长,是不表示,对用户的影响大呢?
萝卜兔:嗯嗯,话是这么说的,可实际是,上报的问题,卡顿耗时特别大的,上报个例只有一两例。上报量最大的,卡顿耗时普遍比较小,接近阈值。而且分析这些堆栈,一般情况下,不应该耗时那么大的。
土豆:所以你需要用了卡顿问题列表新特性,Top分析能力了。还记得二八原则吗?80%的上报集中在20%的问题上,所以你只需要聚焦Top问题。这些Top问题首先从上报量表现这是一个用户容易遇到的问题,而不会受个例特殊环境的影响。这样,你的注意力也从几万个问题聚焦在2000个问题以内。
技能4:聚焦Top问题。
萝卜兔:那我怎么以知道,应该选取Top多少好呢?这样不至于错过严重问题,同时关注的问题又尽可能少呢?
土豆:问题列表查询结果中,会对符号筛选条件的问题进行描述,其中包含一个Top值的推荐,你可以基于这个推荐的Top值来分析。比如下例,27779个问题中,Top1000的问题就包含92.76%的个例上报了。那说明你只需要分析这1000个问题就好了。
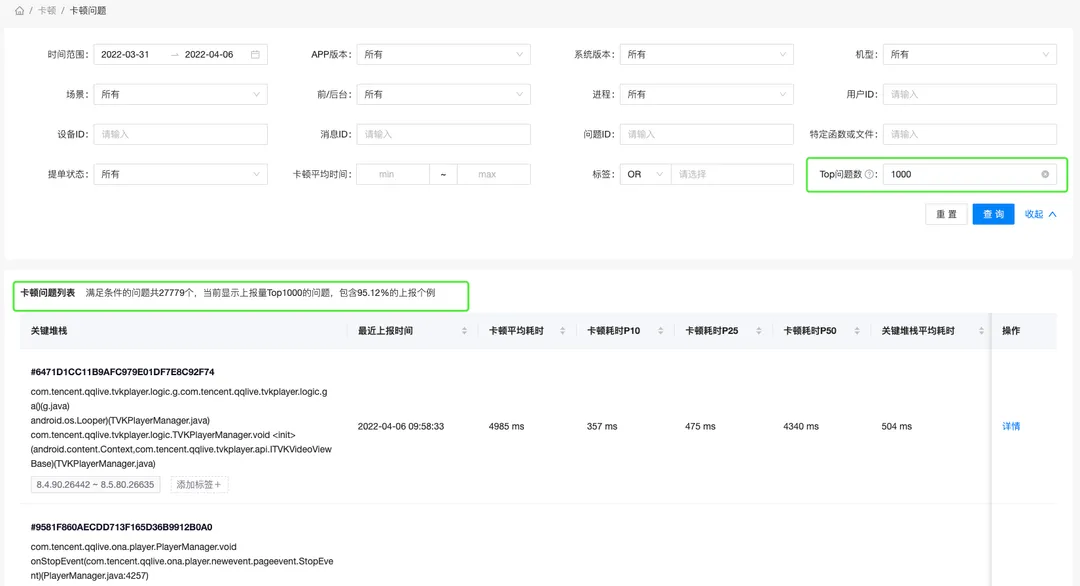
技能5:根据查询结果的Top推荐,选择合适的Top值。
萝卜兔:哗,真是太方便了。这样,我很轻松就知道,应该关注Top多少的问题了。土豆,这些P10, P25,P50是什么意思呢?
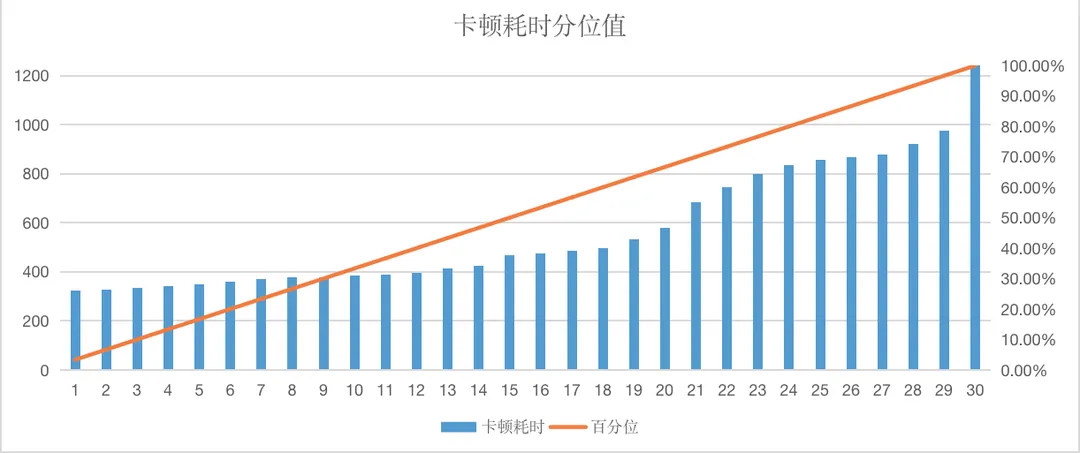
土豆:P10, P25,P50是表示分位数。分位数(Quantile),亦称分位点,是指将一个随机变量的概率分布范围分为几个等份的数值点,常用的有中位数(即二分位数)、四分位数、百分位数等。这里Bugly平台使用的是百分位数。百分位数是统计学术语,如果将一组数据从小到大排序,并计算相应的累计百分位,则某一百分位所对应数据的值就称为这一百分位的百分位数。以卡顿耗时来说,一个问题包含多个例上报,每个个例上报的耗时都不是完全相同的。我们可以将这一个个的上例上报的卡顿耗时,从小到大进行排序,如下图所示,共30个上报,P50 = 排序15对应的卡顿耗时468ms。
萝卜兔:那什么是关键堆栈耗时呢?
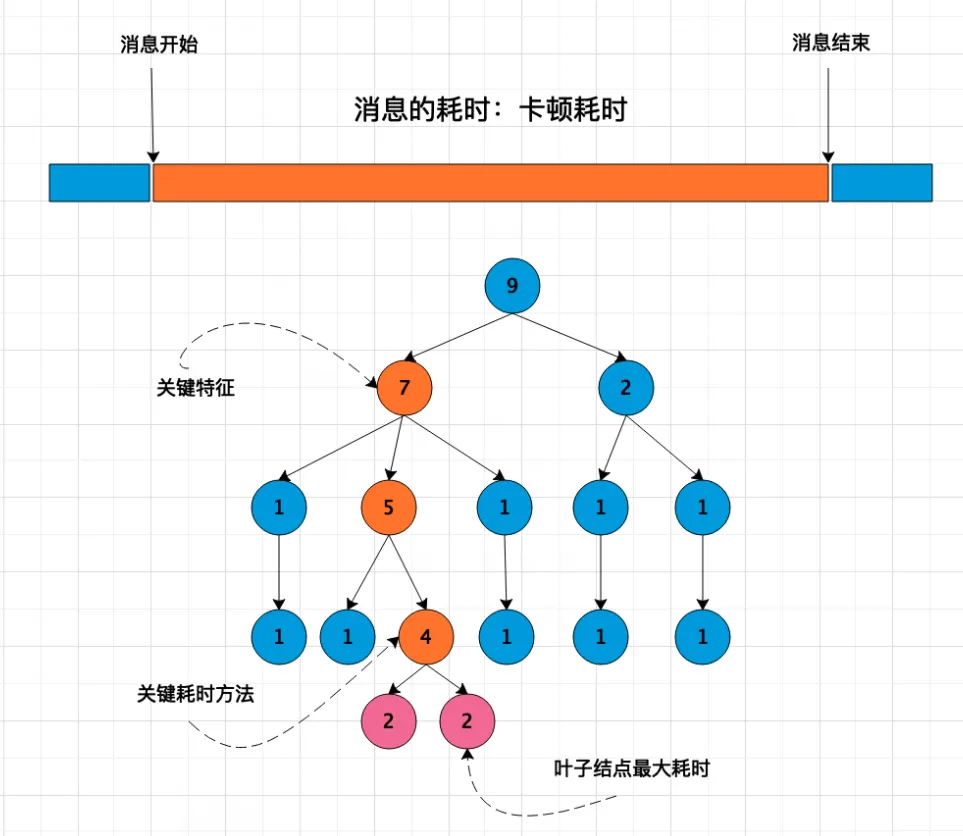
土豆:根据前面的监控原理,每一个个例包含的是不是一棵堆栈树。为了聚合问题,需要抽取特征。导致卡顿的主要原因是不是就是关键堆栈。如下所示,以下就是这个个例的关键堆栈了。有关特征提取的算法,我后面再慢慢跟你说吧,这是一门很深的学问。现在你知道,什么是关键堆栈耗时了吧?
com.example.test.mainlooper.CostJobStrategy.doCostJob(CostJobStrategy.kt:46)
com.example.test.base.CostTask.run(CostTask.java:57)
com.example.test.mainlooper.CostTestThree.run(CostTestThree.java:32)
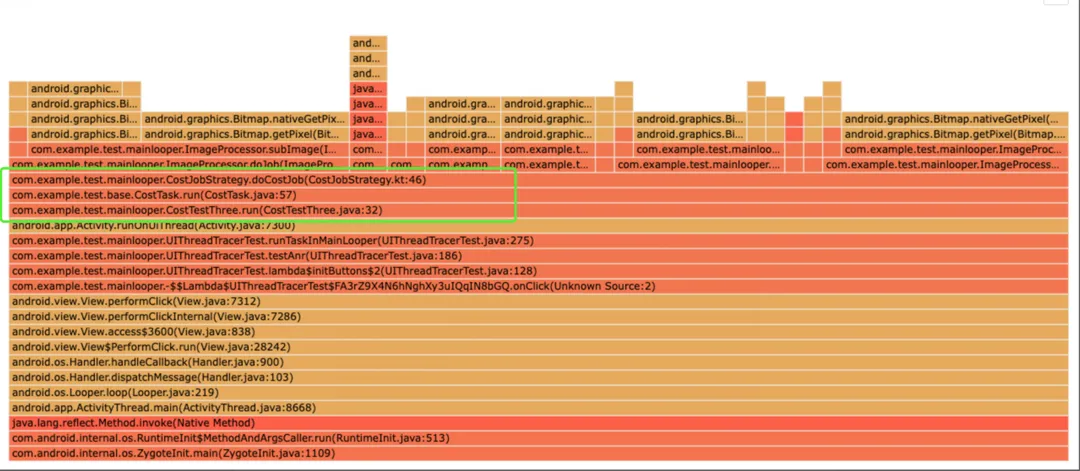
萝卜兔:嗯嗯,明白了,就是在堆栈树上,这段特征的耗时。那叶子结点最大耗时就显而易见了,就是这棵堆栈树上,耗时最大的叶子结点的耗时。
技能6:理解问题列表的统计维度。
萝卜兔:如果我想先解决一波,UI线程IO操作,访问DB,锁等待等相关的问题,我应该在Top1000的问题中,按叶子结点最大耗时P50排序,优先查看排在前面的问题。
土豆:你说的没错,想分析单点耗时问题,可以按叶子结点最大耗时P50排序。这个时候你留意分析,会发现这些问题,往往关键堆栈耗时P50,跟叶子结点最大耗时P50是差不多的。
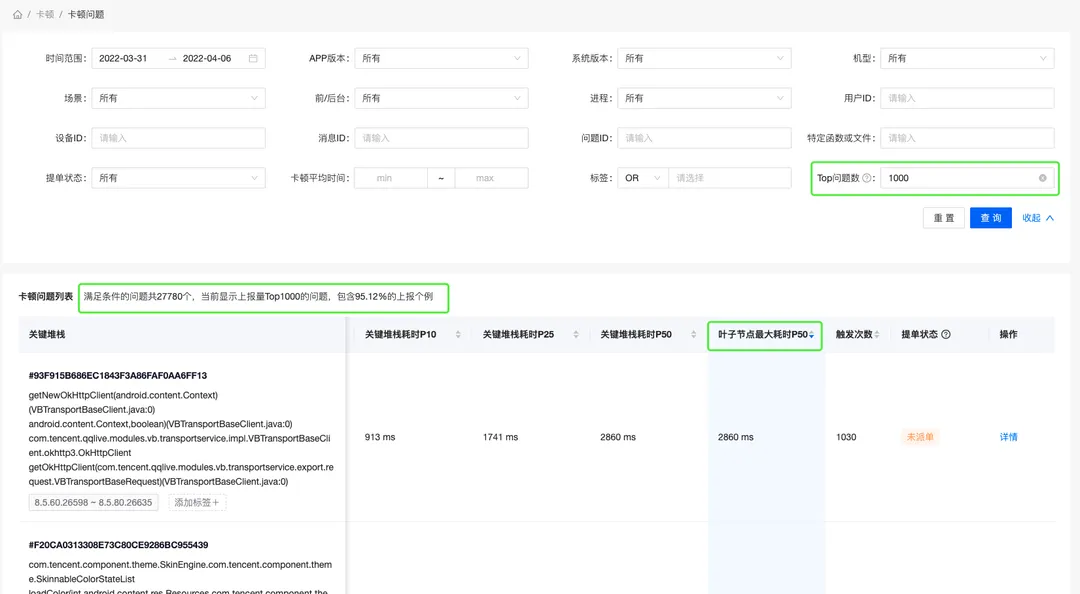
萝卜兔使用后发现,除了叶子结点最大耗时P50,还有卡顿平均耗时,卡顿耗时P10, 卡顿耗时P25,卡顿耗时P50,关键堆栈平均耗时,关键堆栈耗时P10, 关键堆栈耗时P25和关键堆栈耗时P50等维度可以分析。
技能7:按叶子结点最大耗时P50排序,分析单点耗时问题。结合实际需求,多维度分析问题列表,聚焦头部问题。
萝卜兔:我还是有问题,现在发现有些问题聚在了基础组件里。例如下面的SP组件,导致问题原因是这些业务逻辑使用不规范,而非基础组件的问题。我应该怎么办呢?这个问题包含多个业务逻辑,我也不知道应该把单提给谁呀。
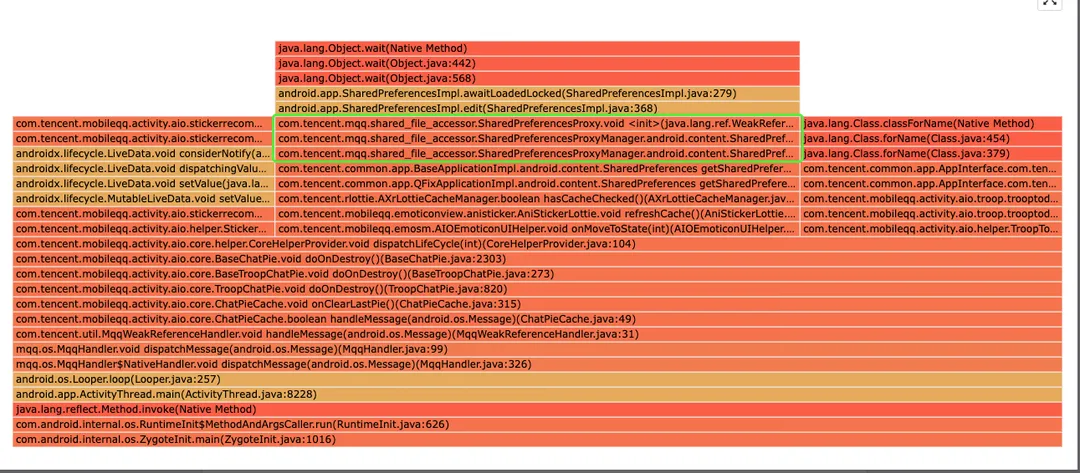
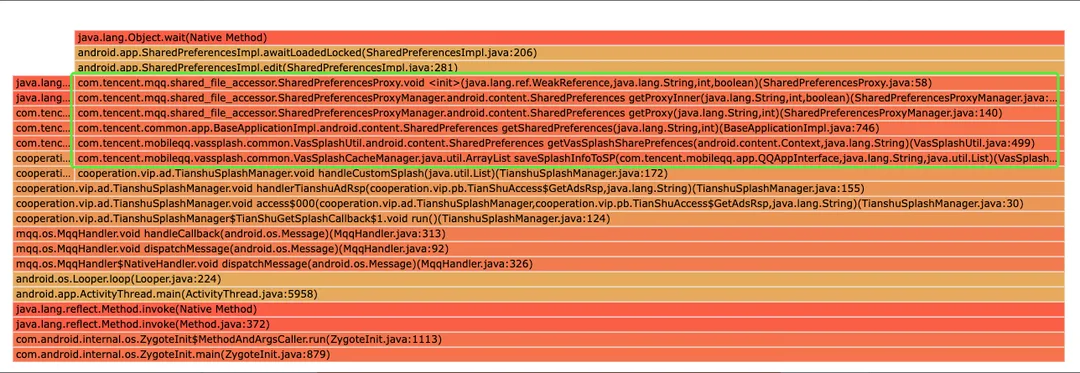
土豆:卡顿提取关键特征时,有一个重要原则,尽可能聚合在业务逻辑里。但是,对于Bugly平台来说,除了系统堆栈,其他的都属于业务堆栈。这种业务的基础组件,可以发邮件申请配置一个业务白名单哦。这样聚合的时候就尽可能排除白名单中的类或者方法。像你提的这个问题,就可以将com.tencent.mqq.shared_file_accessor.SharedPreferencesProxy 和 com.tencent.mqq.shared_file_accessor.SharedPreferencesProxyManager配置在白名单中。或者,如果com.tencent.mqq.shared_file_accessor整个包名下的类都需要排除,也可以将整个包名配置在白名单中哦。
技能8:通过白名单配置,避免问题聚合在基础组件中,以更好归因。
萝卜兔:通过这些分析维度,找到很多问题,我不可能一下子提很多单,开发会找我的麻烦的。
土豆:冰冻三尺,非一日之寒。前面提到的技能3,优先防止新问题产生,逐步推动历史问题解决,难道你就这么快忘了吗?可以优先关注,当前版本新产生的问题。在筛选项时,选定版本,然后打开【只显示新增问题】的开关,即过滤出当前版本新增的问题了。后续Bugly卡顿监控会推出,版本对比,卡顿聚类以及聚类对比功能。你可以分析历史问题的变化趋势,是变严重了,还是冶理生效,问题得到改善了。
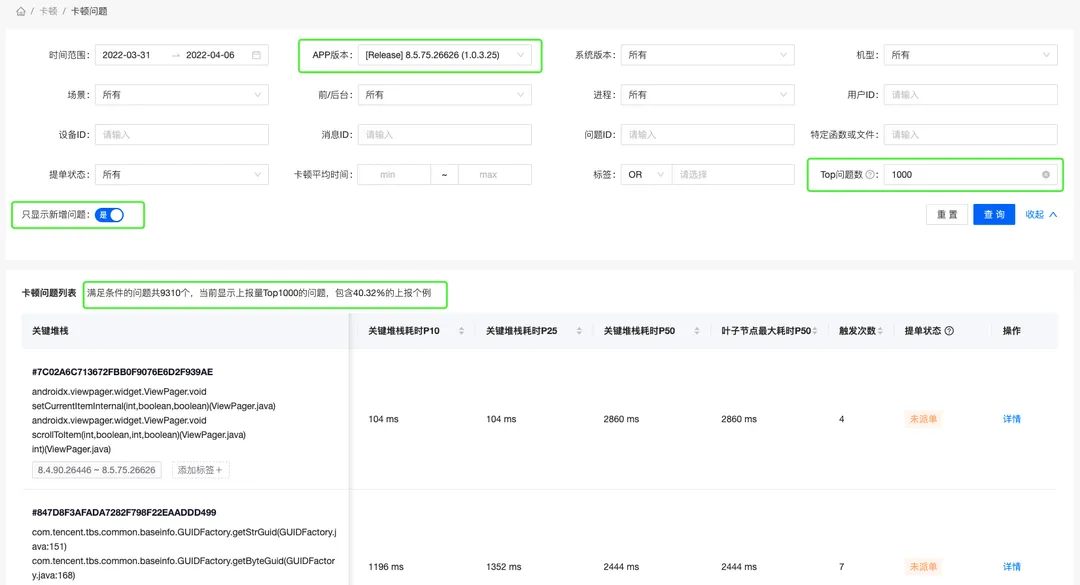
萝卜兔:哗,还规划着这么好用的功能,好期待哦!那我以后,可以早点下班了。
技能9:优先关注版本新增问题。
提升分析卡顿问题效率的八大技能
我们重温一下,提升分析卡顿问题效率的八大技能:
技能1:卡顿治过程中,分阶段调整卡顿阈值。
技能2:优先解决对用户体验影响大的,影响面广的问题。
技能3:优先防止新问题产生,逐步推动历史问题解决。
技能4:聚焦Top问题。
技能5:根据查询结果的Top推荐,选择合适的Top值。
技能6:理解问题列表的统计维度。
技能7:按叶子结点最大耗时P50排序,分析单点耗时问题。结合实际需求,多维度分析问题列表,聚焦头部问题。
技能8:通过白名单配置,避免问题聚合在基础组件中,以更好归因。
技能9: 优先关注版本新增问题。
通过解锁这九大技能,萝卜兔轻松愉快地完成了今天的工作,哼着小曲,准备下班了。你是不是也想体验一下,欢迎使用 Bugly的演示Demo。